% tar -jx < *.bz
Bienvenue sur mon petit coin d'Internet. J'y poste quelques trucs plus (ou parfois moins) utiles, concernant mes geekeries.
Notes, penses-bêtes et divagations
Handling binary documents having ASCII-compatible markup
Écrit le vendredi 9 août 2024.
Python3 has bytes, which are sequences of 8-bit integers, and str,
sequences of Unicode code-points. To go from one to the other, you need to
encode or decode by giving an explicit encoding. There are many protocols
where the markup is ASCII, even if the data is some other encoding that you
don't know. If you know that other encoding is ASCII-compatible, it is useful
to be able to parse, split etc. the markup, and you just need to pass-through
the payload.
An initial search on the Internet brought up an article by Eric S. Raymond
that touches on that, and suggests to decode the data as ISO-8859-1, handle it
as str, then the payload can be losslessly recovered by reencoding it.
ISO-8859-1 has the property that each byte of the input is exactly one
codepoint; and that all 256 possible values are mapped to a code point. As a
result, the following is idempotent:
>>> by = bytes(range(0xff)) >>> by2 = bytes(str(by, encoding="iso-8859-1"), encoding="iso-8859-1") >>> by == by2 True
A few days later I came across that article by Alyssa Coghlan, which mentions
the same idea, and also the existence of the errors="surrogateencoding" (PEP
383) error handler (also: codecs in the Python documentation), which is
designed to allow exactly what I needed:
>>> by = bytes(range(0xff)) >>> by2 = bytes(str(by, encoding="ascii", errors="surrogateescape"), encoding="ascii", errors="surrogateescape") >>> by == by2 True
Alyssa Coghlan has some discussion about the merits of each approach, I can't
really say that functionally they have any meaningful difference. As she
points out, if you do anything but re-encode the non-ASCII compatible parts
using the same codec, you risk getting Mobijake (or if you're lucky, a
UnicodeDecodeError rather than silently producing garbage).
Performance-wise, let's see:
>>> import timeit
>>> timeit.timeit("""bytes(str(by, encoding="ISO-8859-1"), encoding="ISO-8859-1")""", setup="import random; by = random.randbytes(10_000)")
0.8885893229962676
>>> timeit.timeit("""bytes(str(by, encoding="ascii", errors="surrogateescape"), encoding="ascii", errors="surrogateescape")""", setup="import random; by = random.randbytes(10_000)")
125.00223343299876
That's… a very large difference. ESR's article points out that ISO-8859-1 has some properties that make it some efficient (it maps bytes 0x80—0xff to Unicode code-points of the same numeric value, so there is no translation cost, and the in-memory representation is more efficient). Trying increasing sizes:
>>> for size in 10, 100, 1_000, 2_000, 5_000, 10_000, 20_000:
... by = random.randbytes(size)
... duration = timeit.timeit("""bytes(str(by, encoding="ascii", errors="surrogateescape"), encoding="ascii", errors="surrogateescape")""", globals={"by": by}, number=100_000)
... print(f"{size}\t{duration}")
...
10 0.0650910490003298
100 0.1047916579991579
1000 0.5472217770002317
2000 1.5103355319952243
5000 5.779067411000142
10000 12.497241530996689
20000 25.78209423399676
That seems to grow faster than O(n); the duration seems to be ×3 when the size goes ×2, is it growing like O(n1.5)?
In contrast, using the ISO-8859-1 method seems to having a complexity O(n):
>>> for size in 10, 100, 1_000, 2_000, 5_000, 10_000, 20_000, 50_000, 100_000:
... by = random.randbytes(size)
... duration = timeit.timeit("""bytes(str(by, encoding="iso-8859-1"), encoding="iso-8859-1")""", globals={"by": by}, number=100_000)
... print(f"{size}\t{duration}")
...
10 0.05453772499458864
100 0.037617702000716235
1000 0.05454556500626495
2000 0.05654650100041181
5000 0.06352802200126462
10000 0.0898260960020707
20000 0.23981017799815163
50000 0.4997737009980483
100000 0.9646763860000647
TIL: set -u in bash
Écrit le lundi 1 avril 2024.
Trying a new Today I learned section… Today, I learned about set -u,
which will fail a bash script if we try to use a variable that's not defined.
No more deleting someone's files because a variable was not defined. Demo:
#!/bin/bash set -u GREETING=Hello #oups I misspelt that echo ${GREETINGS} world
If you run this:
$ ./script ./script: line 7: GREETINGS: unbound variable
That makes testing whether a variable is set slightly more complicated:
set -u if [[ -z ${GREETINGS} ]]; then # oups we never get here, the previous line fails with "unbound variable" GREETINGS=$( ....compute greetings ...) fi
Instead:
set -u if [[ ! -v GREETINGS ]]; then GREETINGS=$( ... compute greetings ... ) fi
Where -v is a Bash Conditional Expression described thusly:
- -v varname
- True if the shell variable varname is set (has been assigned a value).
I suppose the actually equivalent test would be:
\[\[ ! -v GREETINGS ]] || \[\[ -z ${GREETINGS} ]],
to check whether the variable is not only set but also non-null.
I've always used set -e and set -o pipefail in shell scripts. The first
will exit the entire script if any command (more specifically: any pipeline
fails). However by default, quoting the manual: the "exit status of a pipeline
is the exit status of the last command in the pipeline", meaning the following
succeeds:
$ false | true $ echo $? 0
But, if "pipefail is enabled, the pipeline's return status is the value of
the last (rightmost) command to exit with a non-zero status, or zero if all
commands exit successfully", so:
$ set -o pipefail $ false | true $ echo $? 1
TL;DR: Use set -euo pipefail at the top of your bash scripts. Julia Evans
agrees.
Type stubs for RPi.GPIO
Écrit le samedi 30 mars 2024.
RPi.GPIO is a Python module for controlling GPIO pins on Raspberry Pi. It is old and little maintained (they still use sourceforge.net!), but still useful today. It doesn't have type hints, so I added stubs for RPi.GPIO, now available on PyPI.
Incidentally I learned of distribution name normalisation. Package names can
use ASCII letters, numbers, and ., - and _; but the normalised name is
lower-cased with any run of punctuation characters replaced with a single
dash, so rpi-gpio is the normal form for RPi.GPIO. pip the CLI tool and the
PyPI web interface accept any form: pip install RPi.GPIO, or pip install
rpi-gpio, or pip install rPi__GpIo will install the same package.
pip-compile with use the normalized name when writing a constraints file.
Tunnels IPv6 pour la maison
Écrit le samedi 15 décembre 2012.
J'ai voulu avoir de l'IPv6 à la maison. Mon opérateur Internet ne fournit que de l'IPv4, il faut donc tunneller d'une façon ou d'une autre. J'ai une Kimsufi à disposition, avec un accès IPv6 natif, j'ai donc voulu l'utiliser comme point de sortie.
Bien sûr, une solution est d'utiliser un fournisseur de tunnel comme HE ou SixXS, mais où est l'intérêt de ne pas faire les choses soi-même ?
Creusage de tunnels
Beaucoup de technologies qui permettent de faire des tunnels IPv6 à travers un réseau IPv4 :
| Nom | Type | Usage |
|---|---|---|
| 6in4 | Routeur - Routeur | Un lien IPv6 (typiquement entre routeurs) explicitement configuré entre les deux extrémités |
| GRE | Routeur - Routeur | Une technique d'encapsulation générique Cisco (depuis normalisée) avec quelques fonctionnalités en plus |
| 6to4 | Routeur - Internet | Un lien IPv6, les adresses sont dans 2002::⁄32 et on inclut dans l'adresse IPv6 l'adresse IPv4 (publique !) du routeur. Il y a besoin de relais sur l'Internet (pour le sens Internet -> Routeur) |
| ISATAP | Hôte - Hôte | Deux hôtes (éventuellement routeurs pour leurs réseaux respectifs) qui peuvent se parler en IPv4, avec quelques options d'autoconfiguration. Prévu pour un réseau local. |
| 6over4 | Hôte - Hôte | Comme ISATAP, mais les hôtes doivent se parler en IPv4 multicast (typiquement, ils sont sur le même LAN). Pas intéressant par rapport à ISATAP, mais historiquement le premier. |
| Teredo | Hôte - Internet | Un hôte (éventuellement derrière un NAT) qui accède à l'Internetv6 |
| IPsec | Routeur - Routeur | Initialement prévu pour créer un tunnel sécurisé entre deux réseaux |
Quand on a un point de sortie, la technique idéale est 6in4, ou éventuellement IPsec en mode authentification (le chiffrement est peu intéressant, puisque couvrant uniquement la partie du trafic de la maison au point de sortie, et uniquement pour l'IPv6…).
Plan du réseau
Le serveur / point de sortie utilise lui-même des adresses IPv6. Le réseau côté maison a besoin d'au moins deux préfixes, pour le Wifi et pour le filaire. Or, OVH ne fournit aux kimsufi qu'un seul /64… Il va donc falloir découper en plusieurs morceaux. J'ai choisi /80, attribué comme suit :
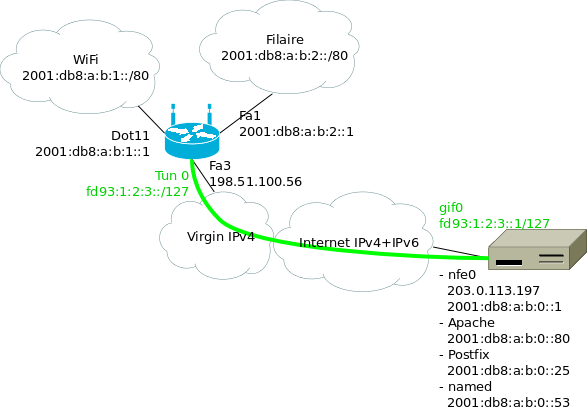
Où :
- 2001:db8:a:b::/64 est le préfixe attribué au point de sortie ;
- le premier /80 est attribué aux différents services qui tournent sur la machine ;
- les /80 suivants pour la maison ;
- en vert le tunnel entre le routeur Wifi à la maison et le point de sortie ;
J'ai utilisé des adresses ULA pour les extrémités du tunnels, mais en
fait il n'y en a pas vraiment besoin : une fois qu'on a commencé à
découper notre /64, autant aller jusqu'au bout. Ça permet juste de
bien reconnaître les adresses dans les fichiers de configuration et
dans les tcpdump.
Problèmes
Il y a deux problèmes avec cette façon de faire. Le premier est évident : on utilise des préfixes qui font plus que /64. Cela nous fait essentiellement perdre les mécanismes d'auto-configuration sur les réseaux de la maison.
Le deuxième est un peu plus subtile. Le /64 fournit par OVH n'est pas vraiment routé jusqu'à nous. Si c'était le cas, tous les paquets à destination du /64 seraient livrés à 2001:db8:a:b::1 (par exemple), et notre routage interne avec les /80 lui serait transparent. À la place, le dernier routeur s'attend à être directement connecté à ce /64, et à pouvoir faire directement un NS et recevoir une réponse pour chaque adresse. Il va donc falloir mettre en place sur l'interface externe un proxy NDP, qui fera croire au routeur que toutes les adresses sont directement connectées.
Implémentation
- Routage sur le point de sortie
On va configurer les adresses que l'on utilise sur la machine comme des /128 (ou éventuellement comme des /80, enfin bref), créer le tunnel, et ajouter les routes statiques vers la maison.
Quelques lignes dans
rc.conf:ifconfig_nfe0="inet 203.0.113.197/24" defaultrouter="203.0.113.254" ifconfig_nfe0_ipv6="inet6 auto_linklocal" # entree statique pour le routeur : # http://travaux.ovh.net/?do=details&id=6819 #rtsold_enable="YES" ipv6_defaultrouter="fe80::5:73ff:fea0:0%nfe0" ifconfig_nfe0_alias0="inet6 2001:db8:a:b::1/128" ifconfig_nfe0_alias1="inet6 2001:db8:a:b::22/128" ifconfig_nfe0_alias2="inet6 2001:db8:a:b::25/128" ifconfig_nfe0_alias3="inet6 2001:db8:a:b::80/128" # tunnel vers la maison gif_interfaces="gif0" gifconfig_gif0="203.0.113.197 198.51.100.56" ifconfig_gif0="mtu 1480" ifconfig_gif0_ipv6="inet6 -auto_linklocal" ifconfig_gif0_alias0="fd93:1:2:3::1/127" ipv6_gateway_enable="YES" ipv6_static_routes="home_wifi home_wired" ipv6_route_home_wifi="2001:db8:a:b:1:: -prefixlen 80 fd93:1:2:3::" ipv6_route_home_wired="2001:db8:a:b:2:: -prefixlen 80 fd93:1:2:3::"
Si pf(4) tourne, on ajoutera :
table <home_nets> const persist { 2001:db8:a:b:1::/80 2001:db8:a:b:2::/80 } extif = "nfe0" tunif = "gif0" # Tunnel 6in4 vers maison pass on $extif proto ipv6 pass from <home_nets> to any pass from any to <home_nets> # Éventuellement des règles plus restrictives pour contrôler ce qui # arrive à la maison
- Configuration du routeur wifi
Le routeur est un Cisco 877W qui fait tourner 15.1(3)T4. En 12.2, j'ai vu que parfois, le routeur décide de ne pas répondre aux NS, ce qui est un peu gênant. On utilise DHCPv6 pour distribuer les adresses. L'interface Wi-Fi ne peut pas être configurée en IPv6, mais on peut la placer dans un bridge qui, lui, peut être configuré avec IPv6.
ipv6 unicast-routing ipv6 cef ! interface Dot11Radio0 description wireless bridge-group 1 ssid Coloc ! interface BVI 1 description bridge pour wireless ipv6 mtu 1480 ipv6 address 2001:DB8:A:B:1::1/80 ipv6 nd autoconfig default-route ipv6 nd managed-config-flag ipv6 dhcp server HOME_WLANv6 ! interface Vlan20 description vlan wired ipv6 mtu 1480 ipv6 address 2001:DB8:A:B:2::1/80 ipv6 nd managed-config-flag ipv6 dhcp server HOME_WIREDv6 ! interface range FastEthernet 0 - 2 switchport mode access switchport access vlan 20 description wired (vlan 20) spanning-tree portfast ! interface Vlan10 description vlan internet ip address dhcp ! interface FastEthernet3 description internet (vlan 10) switchport access vlan 10 ! interface Tunnel0 description tunnel vers serveur no ip address ipv6 address FD93:1:2:3::/127 tunnel source Vlan10 tunnel destination 203.0.113.197 tunnel mode ipv6ip ! ipv6 dhcp pool HOME_WIREDv6 address prefix 2001:DB8:A:B:2::/80 dns-server 2001:DB8:A:B::53 ! ipv6 dhcp pool HOME_WLANv6 address prefix 2001:DB8:A:B:1::/80 dns-server 2001:DB8:A:B::53 ! ipv6 route ::/0 FD93:1:2:3::1/127
Les interfaces Fa 0 - 2, utilisées pour le LAN filaire, sont mises en
portfast. Sans leportfast, il faut ≈45 secondes à STP pour accepter que je n'ai pas créé de boucle en branchant mon portable. NetworkManager envoie n RS avec un timeout de t secondes pour la réponse RA. Avec n = 3, t = 1 seconde (RFC2461), NetworkManager a le temps d'abandonner plusieurs fois… Donc on passe enportfast. - Proxy NDP
Comme mentionné plus haut, l'un des soucis est que le routeur devant la KS s'attend à voir le /64 complètement à plat. Il faut donc un proxy NDP qui réponde à la place des machines qui sont à la maison.
Ça fait environ 300 lignes pour un programme qui écoute avec
libpcaples NS sur l'interface externe et qui envoie les NA correspondants. Le code est dans un dépôt git (ou interface gitweb). Avec le réseau montré plus haut, j'appellendp6avec les options :ndp6 -i nfe0 -p 2001:db8:a:b:1::/80 -p 2001:db8:a:b:2::/80
Les gens qui utilisent Linux sur le point de sortie seront intéressés par ndppd. Parmi les linuxeries, il y a la lecture de
/proc/net/ipv6_routepour mettre à jour les réseaux proxifiés, l'utilisation d'unesocketAF_PACKETpour écouter les paquets qui ne nous sont pas destinés.
Soucis rencontrés
- Clients DHCP
Avec ISC dhclient, lorsqu'une adresse est configurée par DHCPv6, elle est installée avec un préfixe en /64. C'est un bug dans le client DHCP (les annonces DHCP ne contiennent qu'une adresse, pas d'informations sur le lien local). La RFC 5942, section 5 explique le problème, disant que c'est ce qui arrive quand « the IPv6 subnet model is not understood by the implementers of several popular host operating systems ».
Le bug Debian #684009 contient un patch pour ISC dhclient (apparemment remonté upstream). De son côté, Network Manager ne fait ples confiance aux préfixes annoncé par les clients DHCPv6.
Le client WIDE dhcp6c a le bon comportement (à condition de lui dire de demander une adresse…), je n'ai pas testé son intégration avec Network Manager.
Le Windows 7 du boulot semble avoir le bon comportement.
- Bizarrerie sur le DHCP côte WAN
Les serveurs DHCP de chez Virgin Media se comportent bizarrement. En particulier, après une coupure de courant, le routeur ne reçoit pas d'adresse jusqu'à ce que le modem câble se fasse rebooter. Pas quelque chose que je peux corriger de mon côté…
ZFS pour des mises à jour sereines
Écrit le samedi 2 juin 2012, modifié le lundi 11 mars 2024.
Avec FreeBSD 9.0 qui est sorti il y a presque six mois, il est grand temps de se mettre à jour. On ne peut pas à la fois prétendre au status de cyborg, et utiliser autre chose que la dernière version de son OS préféré !
Dans un épisode précédent on avait installé son serveur avec ZFS, justement pour pouvoir faire des mises à jour avec une solution de repli si les choses tournent mal. On a deux solutions : faire un snapshot puis mettre à jour, avec la possibilité de faire un rollback plus tard ; ou alors installer dans un nouveau volume et pointer le bootloader sur le nouvel environnement. J'ai exploré la deuxième option. Cette deuxième option permet de ne pas tout perdre s'il faut revenir en arrière. On verra dans la suite si cela devait se révéler utile…
Préparation
Histoire d'avoir les ports déjà construits, on installe poudriere, la configuration se résume à pointer sur un FTP proche de chez nous. Ensuite on prépare un environnement pour 9.0 :
poudriere jail -c -v 9.0-RELEASE -a amd64 -j poudre90 poudriere ports -c
On récupère la liste des ports installés, et tant qu'on y est on récupère aussi leur configuration pour que poudriere reconstruise les ports avec les bonnes options.
(pkg_version -o; jexecall pkg_version -o) >portlist sort <portlist| uniq >portlistuniq cut -d' ' -f1 <portlistuniq >portlist cp -r /srv/jails/*/var/db/ports/* /usr/local/etc/poudriere.d/options poudriere bulk -f portlist
Le système de base
Pendant que poudriere mouline, on installe FreeBSD 9.0 sur un système de fichiers à part.
zfs create zroot/slash90
zfs set mountpoint=/slash90 zroot/slash90
zfs create zroot/slash90/usr
cd /slash90
fetch http://ftp.fr.freebsd.org/pub/FreeBSD/releases/amd64/amd64/9.0-RELEASE/{base,kernel,src}.txz
tar -xpf base.txz
tar -xpf kernel.txz
tar -xpf src.txz
Pour les fichiers de configuration, on va copier la configuration
depuis notre environnement actuel vers l'installation toute fraîche,
puis lancer un coup de mergemaster(8) :
cd /slash90/etc cp -a /etc/ . chroot /slash90 mergaster -FUvi
On profite également d'être dans un chroot dans /slash90 pour
installer les ports qu'on vient de construire.
La configuration réseau a un peu changé. Une configuration avec plusieurs addresses dans chaque famille ressemble à :
ifconfig_nfe0="inet 203.0.113.13/24" defaultrouter="203.0.113.254" ifconfig_nfe0_ipv6="inet6 2001:db8:1:8248::1/64 accept_rtadv" rtsold_enable="YES" # ou ipv6_defaultrouter="fe80::f00:baa%nfe0" ifconfig_nfe0_alias0="inet 198.51.100.43/32" ifconfig_nfe0_alias1="inet6 2001:db8:1:8248::25" ifconfig_nfe0_alias2="inet6 2001:db8:1:8248::53"
ipv6_network_interfaces n'est plus nécessaire.
On copie également /usr/local/etc dans /slash90.
Bascule vers 9.0
Pour basculer d'un environnement vers l'autre, il suffit1 de faire :
zfs set canmount=noauto zroot/slash82 zfs set canmount=noauto zroot/slash82/usr vi /slash90/boot/loader.conf # Ajouter : zfs_load="YES" # et : vfs.root.mountfrom="zfs:zroot/slash90" zfs unmount zroot/slash90 zfs unmount zroot/slash90/usr zfs set mountpoint=/ zroot/slash90 zfs set mountpoint=/usr zroot/slash90/usr zpool set bootfs=zroot/slash90 zroot
Dans mon cas, l'environnement actuel est installé dans
zroot/slash82, avec /usr qui est dans zroot/slash82/usr. Si la
racine du système est directement à la racine du pool ZFS, il y aura
quelques subtilités, si on passe zroot en noauto il faudra penser
à modifier les autres points de montage par exemple. De plus, chez moi
/var est dans zroot/var, monté automatiquement par ZFS, donc il
n'y a pas besoin de le déplacer.
Au premier essai, ma kimsufi n'a pas démarré. Un peu d'investigation
via le le mode rescue-pro d'OVH (un simple netboot avec les
disques accessibles) ne donne rien. Un zpool import -o altroot=/mnt
plus tard, on refait la bascule dans l'autre sens (en utilisant
zroot/slash82), et on retrouve une machine qui boote.
Le lendemain, je retente l'opération, cette fois en vKVM (une machine virtuelle qui démarre sur le disque dur du serveur), et là… le démarrage se passe correctement. Je ne sais pas pourquoi au premier essai, les choses se sont bloquées au boot.
Après un peu d'exploration, on voit qu'il y a certaines choses qui ont été « perdues » :
- ce qui est dans
/root(un script de sauvegarde, par exemple) ; - ce qui est dans
/usr/local. J'ai pensé auxportset à leur configuration, mais j'ai laissé de côté le RTM d'OVH, les dossiers de données depoudriere… ; /home(qui ne contenait guère que~fred/.ssh/authorized_keysd'intéressant).
Il suffit de monter zroot/slash82 (qui est actuellement en
canmount=noauto) pour avoir accès à ses données et les réinstaller.
Les jails
On pourrait tout à fait adopter la même procédure : installer dans un système de fichiers à part, y compris les ports, rapatrier les configurations, et pointer ezjail vers la nouvelle installation. La mise à jour en place semble plus simple, et tellement moins risquée que pour la machine hôte…
ezjail-admin update -s 8.2-RELEASE -U
Attention, freebsd-update essaie de mettre à jour le noyau, il faut
le relancer à la main une deuxième fois.
Malheureusement, il faut lancer à la main mergemaster pour chacune
des jails (et tant qu'on y pense, mettre à jour le gabarit
d'ezjail).
Pour les ports, grâce à la préparation faite plus haut, on a déjà des
packages binaires à jour pour nos jails, et il suffit de lancer un
jexecall portmaster -a pour tout mettre à jour.
Conclusion
Le passage à 9.0 n'a pas été aussi facile qu'attendu. En particulier,
je ne sais pas pourquoi le premier démarrage n'a pas réussi du premier
coup, et si c'est dû à l'utilisation de ZFS ou pas. De plus, la
méthode que j'ai suivie n'était pas idéale —je suppose qu'en ayant de
vraies procédures de backup-restore, je n'aurais pas oublié RTM ou
les scripts qui traînent dans /root. D'un autre côté, le paramètre
bootfs plus jouer un peu avec les points de montage permet de
basculer facilement d'une installation à l'autre ; c'était une
promesse de ZFS, et cette promesse est tenue. Au premier essai, c'est
ce qui m'a permis de revenir sur une configuration fonctionnelle.
Je regrette de ne pas avoir adopté poudriere plus tôt.
Notes d'EuroBSDcon 2011
Écrit le dimanche 30 octobre 2011.
EuroBSDcon 2011 s'est déroulé au début de ce mois d'octobre. Je viens de finir de mettre en forme mes notes sur les conférences que j'ai suivies.
On y retrouvera en particulier :
- sendmail, history and design, présenté par Eric Allman, dans lequel l'auteur présente l'histoire du MTA qui est encore aujourd'hui le plus utilisé sur Internet, les éléments de design qui ont permis à sendmail de survivre pendant 30 ans, et les élèments malgré lesquels sendmail a survécu pendant 30 ans ;
- Minix 3, ou comment construire un OS fiable, par Herbert Bos : en utilisant des principes systématiques de réduction des privilèges, de séparation des composants, et en acceptant que les composants peuvent crasher mais sont pour la plupart redémarrables ;
- status d'IPv6 dans FreeBSD de Bjoern Zeeb, comment FreeBSD a vécu le
World IPv6 Day cette année, les leçons du noyau
AF_INET6-only, et ce qui doit arriver dans le futur proche dans un FreeBSD près de chez vous ; - portage d'OpenBSD vers UltraSPARC T1 et T2 de Mark Kettenis, une session très technique (au cours de laquelle je ne prétendrais pas avoir tout compris), qui décrit dans une première partie les atouts de cette plateforme, et comment OpenBSD est capable de tourner sur cette architecture ;
- NPF, un nouveau pf pour NetBSD 6.0 de Zoltan Arnold Nagy, qui explique pourquoi un nouveau pare-feu est nécessaire et comment NPF a été construit ;
- High Availability STorage in FreeBSD de Pawel Jakub Dawidek, du RAID1 over network, modes de synchronisation, démonstration, performance ;
- testing automatique de NetBSD de Martin Husemann, les composants logiciels mis en œuvre, les bindings dans différents languages, les bugs découverts grâce au testing systématique.
À noter également les slides de quelques développeurs OpenBSD :
- What's new in OpenSSH, de Damien Miller ;
- OpenBSD's New Suspend and Resume Framework (slides), de Paul Irofti ;
- OpenBSD SCSI Evolution de David Gwynne et Ken Westerback ;
- 10 years of pf, de Ryan McBride et Henning Brauer :
- OpenBSD Update, du même Henning Brauer.
Malheureusement les slides de Claudio Jeker sur MPLS ne sont pas en ligne.
Michael Dexter a parlé de virtualisation dans le monde BSD (plus de documents). Son exposé avait deux grands axes : une classification des techniques de virtualisation existante, et surtout une présentation de BHyVe, un hyperviseur de type 2 (à la Xen) pour FreeBSD.
Installation d'une kimsufi sous FreeBSD en full-ZFS
Écrit le samedi 27 août 2011, modifié le dimanche 18 septembre 2011.
Comme ZFS c'est beau, ça rend le poil soyeux et ça permet à l'admin de
diminuer sa consommation d'aspirine, j'ai profité de mon changement de
Kimsufi pour l'installer en tout ZFS, depuis le boot. Bien sûr, une
solution aurait été de laisser l'installation sur / et de ne mettre
que les données sur un volume ZFS, mais c'est trop facile, ça. Et puis
on garde de l'UFS, c'est so-XX^ième siècle.
Pour installer en tout ZFS, il doit y avoir au moins trois solutions pour faire cette installation :
- partir du système existant et installé, créer un volume, faire un
cpde notre/UFS vers ce volume ZFS, pointer le chargeur de boot vers ce volume ; - booter depuis le réseau (OVH permet de booter sur un FreeBSD 8.2, yay), et faire l'installation comme cela ;
- booter sur vKVM depuis une ISO.
On est d'accord que le premier, c'est tricher. Chez moi le vKVM perdait régulièrement la connexion, alors j'ai utilisé le boot sur le réseau (le mode rescue-pro).
Let's go.
Installation
Cette partie est largement une reprise du wiki de FreeBSD sur l'installation d'un système en ZFS.
Cependant :
- on ne boote pas sur l'ISO d'installation,
- on boote sur une racine qui est en NFS lecture seule.
Il va donc falloir ruser (un peu) pour récupérer les paquets d'installation.
On boote alors sur le rescue-pro, on a bien sûr pris soin de donner sa clef publique SSH pour ne pas avoir à attendre le mail avec les identifiants.
Je n'ai pas réussi à installer ZFS en utilisant une table de partition MBR, alors que ça a marché du premier coup avec du GPT. Il paraît que GPT est la voie du futur, alors hop.
On détruit avec gpart destroy le partitionnement en place, et
on recrée un nouveau schéma :
gpart create -s gpt ad4 gpart add -s 64K -t freebsd-boot ad4 gpart add -s 2G -t freebsd-swap -l swap ad4 glabel label swap ad4p2 gpart add -t freebsd-zfs -l data ad4 glabel label data ad4p3 gpart show
Autre possibilité : ne pas faire de partition de swap, mais créer un volume ZFS de swap. D'après la page du Wiki FreeBSD citée plus haut, ça empêche de créer des dumps lors d'un crash. En l'absence d'autres arguments, je suis parti sur une partition de swap à part.
Récupérer les fichiers d'installation. On crée un volume en tmpfs, et
on ignore couragement l'avertissement qui apparaît dans le dmesg :
mkdir /root/sets mount -t tmpfs -o size=300000000 dummy /root/sets dmesg | tail => WARNING: TMPFS is considered to be a highly experimental feature in FreeBSD. cd sets ftp ftp.fr.freebsd.org cd pub/FreeBSD/releases/amd64/8.2-RELEASE !mkdir base kernels mget base/* kernels/*
Dans mon cas, j'installe juste un hôte minimal pour des jails. Pour un serveur traditionnel, vous voudrez certainement installer les autres sets, mais au pire cela se fait très bien une fois l'installation terminée.
On crée le volume ZFS :
mkdir /root/newinstall zpool create -m /root/newinstall zroot /dev/gpt/data zpool set bootfs=zroot zroot
On crée les sous-volumes ZFS :
zfs create zroot/usr zfs create zroot/var zfs list
On devrait voir zroot monté dans /root/newinstall, zroot/var
dans /root/newinstall, etc.
Encore une fois, pour un serveur complet on voudra peut-être créer
d'autres volumes ZFS pour une séparation plus fine, peut-être un
/var/log compressé ou un /var/empty en RO… Voir l'article du
wiki de FreeBSD pour une idée de partitionnement possible. /home
avec des quotas (voire un volume par luser) est une très bonne idée de
chose à ajouter si on prévoit d'avoir d'autres utilisateurs.
Par contre, mettre la racine (de notre serveur) dans la racine (de notre pool ZFS) n'est pas forcément une très bonne idée. Heureusement, on peut corriger cela plus tard.
On installe le monde de base plus le noyau GENERIC :
setenv DESTDIR /root/newinstall cd /root/sets cd base ; sh install.sh ; cd .. cd kernels ; sh install.sh generic ; cd .. cd /root/newinstall/boot rm -fr kernel mv GENERIC kernel chroot /root/newinstall echo /dev/label/swap none swap sw 0 0 > /etc/fstab echo 'zfs_load="YES"' > /boot/loader.conf echo 'vfs.root.mountfrom="zfs:zroot"' >> /boot/loader.conf vi /etc/rc.conf
sshd_enable="YES" ntpdate_enable="YES" ntpdate_hosts="213.186.33.99" fsck_y_enable="YES" named_enable="YES" ifconfig_nfe0="inet 198.51.100.43/24" defaultrouter="94.23.42.254" hostname="foo.example.net" zfs_enable="YES"
Mettre un mot de passe pour root (passwd), et se créer un
utilisateur (adduser et répondre aux questions). Noter que par
défaut sshd refuse les connexions en tant que root, donc créer un
utilisateur mortel et le placer dans le groupe wheel est
certainement une bonne idée.
Quitter le chroot.
On va installer le bootloader ZFS-capable. Là j'ai eu une surprise :
ZFS s'est mis à utiliser toute la RAM, ce qui est normal vue
l'installation qu'on vient de réaliser, mais au détriment de notre
partition tmpfs, ce qui est étonnant étant donné qu'on a donné une
réservation. Donc, j'ai démonté / remonté mon pool ZFS, mon tmpfs a
retrouvé une taille normale, et j'ai pu récupérer le bootloader pour
l'installer :
zpool export zroot zpool import zroot cp /root/newinstall/boot/pmbr /root/sets cp /root/newinstall/boot/gptzfsboot /root/sets zpool export zroot gpart bootcode -b /root/newinstall/boot/pmbr -p /root/newinstall/boot/gptzfsboot -i 1 ad4 zpool import zroot
Il est peut-être possible d'installer le bootloader sans démonter le
pool, je n'ai pas essayé. Il doit aussi certainement être possible
d'utiliser celui est dans le /boot de l'environnement fourni par
OVH, je n'y ai pas pensé sur le moment…
Il semble que ZFS ait besoin d'un cache pour booter correctement. Je n'ai pas trouvé d'articles expliquant quelle est l'utilité du cache et ce qui se passe s'il n'est pas disponible au boot.
zpool set cachefile=/root/newinstall/boot/zfs/zpool.cache
On remet les points de montage au bon endroit :
zfs set mountpoint=legacy zroot zfs set mountpoint=/usr zroot/usr zfs set mountpoint=/var zroot/var zpool set bootfs=zroot zroot zfs unmount -a
Et là on croise les doigts et on reboote.
Déplacement de la racine vers un autre dataset
Ceci permet de faire plusieurs choses :
- appliquer une réservation d'espace pour la racine ;
- lorsqu'une nouvelle MàJ va arriver, il suffira de l'installer dans un nouveau dataset et de dire au bootloader de prendre l'autre dataset.
Let's roll.
On copie notre racine actuelle dans un autre volume :
zfs snapshot zroot@1 zfs send zroot@1 | zfs receive zroot/slash zfs destroy zroot@1
Même chose pour /usr :
zfs snapshot zroot/usr@1 zfs send zroot/usr@1 | zfs receive zroot/slash/usr zfs destroy zroot/usr@1
Bien sûr, même chose pour les autres FS si vous avez partagé votre
/usr en morceaux.
Il m'a été indiqué que renommer zroot/usr dans zroot/slash/usr
(avec zfs rename) est plus rapide, et surtout évite d'oublier un
volume si /usr a été fractionné.
On indique qu'on veut booter sur zroot/slash :
zpool set bootfs=zroot/slash vi /slash/etc/loader.conf
Et on ajuste la valeur de vfs.root.mountfrom.
On veut aussi changer notre /usr :
zfs set canmount=noauto zroot/usr zfs set mountpoint=/usr zroot/slash/usr
À ce moment, on a deux volumes montés sur /usr. Ça marche, mais
c'est un peu bancal ; on va donc rebooter de suite. Quand la machine
revient, on vérifie avec zfs list et mount que tout est bien
monter là où on l'attend (l'un montre la configuration des points de
montage, et l'autre montre les vrais montages). On voit que
zroot/slash a un mountpoint qui vaut /slash, mais est monté à
/ en vrai. Je ne sais pas à quel point ça peut être gênant.
Pour vérifier que le volume zroot n'est plus directement utilisé, on
va le vider puis vérifier que la machine revient au reboot :
zfs set mountpoint=/whatever zroot chroot /whatever rm -fr * # oups, il y a des fichiers avec l'option schg... ^D chflags -R noschg /whatever rm -fr /whatever/* zfs set mountpoint=none zroot rmdir /whatever zfs destroy zroot/usr reboot
(Attention si vous avez d'autres volumes qui héritent leur point de
montage depuis zroot !)
Notez que je n'ai pas déplacé /var, qui ne sera pas concerné par les
mises à jours. C'est peut-être un choix discutable.
Post-installation
Ensuite, il nous reste toutes les actions habituelles d'une installation FreeBSD :
- configurer
/etc/rc.confpour activer les services que l'on veut ; - installer des jails pour nos serveurs qui vont parler au publique ;
- ajouter l'arbre des ports pour installer des logiciels ;
- (optionnellement) installer RTM d'OVH : http://guide.ovh.com/RealTimeMonitoring ;
Et moultes autres activités :)
Écrire un fichier de complétion pour zsh
Écrit le lundi 20 juin 2011.
zsh est très connu pour son système de complétion très poussé. Malheureusement, zsh n'est pas équipé pour gérer les conventions d'appel de tous les outils qu'on peut trouver sur nos babasses. On peut donc être amené à écrire soi-même une méthode de complétion. Ces notes ont été prises à l'occasion de l'écriture d'un fichier de complétion pour ezjail, et les exemples viennent de là.
Parfois, il n'y a presque rien à faire…
Il y a quelques cas où on n'a presque rien à faire pour bénéficier de
la complétion sur un nouvel outil. Par exemple, si un outil utilise
les conventions GNU, zsh peut parser la sortie de --help pour
obtenir la liste des options existantes. Il suffit pour cela d'ajouter
quelque chose comme :
compdef _gnu_generic foo
dans un fichier lu par zsh (.zshrc conviendra), et de relancer son
shell pour pouvoir compléter les options de foo. On a même le droit
à la documentation des options.
Un autre cas où l'on n'a presque rien à faire est lorsqu'on peut réutiliser une complétion existante. Si un outil attend comme argument uniquement des noms d'hôtes, on utilisera :
compdef _hosts foo
Maintenant, en tapant foo <TAB>, zsh proposera des complétions
basées sur les noms d'hôtes, trouvés par `getent hosts` ou qui sont
dans l'une des bases ssh_known_hosts entre autres.
Dans l'exemple au-dessus, _hosts est le nom d'une fonction zsh, dont
la définition est (sur mon système) dans
/usr/local/share/zsh/4.3.11/functions/Completion/Unix.
La documentation de zsh donne un autre exemple assez courant : le cas d'une commande qui accepte tous les fichiers qui ont une certaine extension.
compdef '_files -g "*.h"' foo
Ici, _files est encore une fonction, définie au même endroit que
_hosts (et bon courage à celui qui voudra se plonger dans le code de
cette fonction…). La documentation de cette fonction est visible
dans le manuel de zsh, au nœud « Completion Functions > Utility
Functions ».
…parfois c'est plus compliqué
Lorsqu'on a des besoins plus poussés, au hasard pour un outil tel
qu'ezjail, on va devoir coder sa propre complétion. Une complétion
n'est en soi qu'une fonction zsh qui est appelée par le shell lorsque
l'utilisateur appuie sur TAB (ou C-d pour afficher les
complétions).
Les fonctions de complétions sont installées par défaut dans
/usr/local/share/zsh/site-functions/ (l'emplacement exact peut
dépendre de votre OS). Par convention, le fichier dans lequel vous
allez écrire votre fonction de complétion a le même nom que la
commande concerné, avec un _ ajouté au début.
Lors du développement d'un fichier de complétion, il sera peut-être
plus pratique de pouvoir éditer le fichier sans être root. Dans ce
cas, il suffit de choisir un dossier local, par exemple ~/zsh. On
placera le fichier de complétion dedans, et on l'ajoute au tableau
$fpath (bien sûr, à placer avant l'appel à compinit) :
fpath=(~/zsh $fpath)
Notons que zsh refusera de charger des fonctions (donc des définitions de complétion) si le fichier appartient à un utilisateur autre que root ou l'utilisateur courant, ou s'il est modifiable par un autre utilisateur.
Le fichier de complétion commence avec un tag spécial sur la première ligne :
#compdef ezjail-admin
C'est un commentaire, qui indique à zsh que le fichier contient une complétion, et bien sûr quelle commande est concernée.
Ensuite, on définit une fonction de complétion, et on l'appelle :
_ezjail () { # code de complétion } _ezjail "$@"
- Informations fournies par le shell aux fonctions de complétions
Notre code, ici la fonction
_ezjail, sera appelée avec quelques informations sur la ligne de commande qui a déjà été saisie par l'utilisateur.Les informations qui sont accessibles depuis le code de complétion seront les suivantes :
Variable Description $wordsLes mots déjà entrés par l'utilisateur $CURRENTL'index, dans $words, du mot que l'utilisateur essaie de compléter (c'est$#wordssauf si l'utilisateur est revenu en arrière)$curcontextUne chaîne de caractères, décrivant le contexte courant Le contexte courant est utilisé en interne à zsh pour savoir comment interpréter les demandes de complétions. Depuis le code de complétion, on passera aussi
$curcontextàzstylepour récupérer les styles de complétion voulus par l'utilisateur. Comme je n'utilise paszstyle, je ne me suis pas beaucoup avancé dans cette direction.Si vous avez sous les yeux le fichier de complétion d'ezjail, vous verrez que la fonction principale,
_ezjail, fait un petit tour de passe-passe sur ces variables pour sauter sur la fonction correspondant à la sous-commande déjà entrée. La plupart des outils pourront certainement se passer d'une telle manipulation. - Renvoyer les candidats à la complétion
Pour renvoyer à zsh les complétions elles-mêmes, on va utiliser l'une des fonctions de complétion. La fonction
_argumentssera notre outil principal, en particulier pour les outils qui ont des options standards.- Exemple typique
Si l'on prend comme exemple la complétion (un peu réorganisée) pour
ezjail-admin create:_ezjail_cmd_create () { _arguments -s : \ "-i[file-based jail]" \ "-x[jail exists, only update the config]" \ "-a[restore from archive]:archive:_files" \ "-c[image type]:imagetype:(bde eli zfs)" \ "-C[image parameters]:imageparams:" \ "-s[size of the jail]:jailsize:" \ ":jail name:" \ ":comma-separated IP addresses:" }
Le
-sdonné à_argumentspermet de dire que pour cette commande, les options courtes peuvent être combinées, i.e.-ixest équivalent à-i -x. Le texte entre crochets est affiché à côté de la complétion, sauf si l'utilisateur a désactivé cela.Dans l'exemple au-dessus,
-iet-xsont des options qui n'attendent pas d'arguments. Les autres options attendent des arguments : on les distingue parce qu'une description de l'argument et une méthode pour compléter cet argument sont données, avec des:pour séparer les champs. Dans le cas de-a, l'argument sera complété par la fonction_files, qui propose des noms de fichiers comme choix. Dans le cas de-c, la completion se fait sur un petit nombre de choix possibles, qui sont donnés entre parenthèses. Pour-C, on indique qu'on attend un mot donné par l'utilisateur, mais le shell n'aidera pas à le compléter.Enfin, la commande prend encore deux arguments, mais on ne sait pas offrir d'aide pour les compléter (il n'y a rien avant le premier
:). - Options mutuellement exclusives
Il peut y avoir des cas où des options sont mutuellement exclusives. C'est le cas pour
ezjail-admin archive: ou bien l'on archive toutes les jails avec-A, ou alors on donne une liste de jails._ezjail_cmd_archive () { _arguments -s : \ "-a[archive name]:archive name:" \ "-d[destination directory]:destination dir:_files -/" \ "-f[archive the jail even if it is running]" \ - archiveall \ "-A[archive all jails]" \ - somejails \ "*:jail:_ezjail_stopped_jails" }
On sépare les groupes d'options qui s'excluent avec un tag (je ne sais pas si le nom est réutilisé pour être montré à l'utilisateur dans certaines circonstances). Les options qui peuvent toujours être utilisées sont données en premier. Remarquez au passage l'astérisque pour la dernière ligne : cela permet d'indiquer qu'on peut avoir des répétitions.
_values: plus simple
Lorsqu'on a juste une liste de mots à proposer, surtout si cette liste est générée dynamiquement, les arguments pour
_argumentsne sont pas faciles à manipuler. Dans ce cas,_values, qui permet de simplement donner la liste des mots candidats à la complétion, est plus facile à manipuler. En prenant comme exemple_ezjail, dans le cas où on propose les sous-commandes, on a :_ezjail () { local cmd if (( CURRENT > 2)); then # déjà un mot complet sur la ligne; sauter à la fonction # spécifique à cette sous-commande. else # on complète la sous-commande _values : \ "archive[create a backup of one or several jails]" \ "config[manage specific jails]" \ "console[attach your console to a running jail]" \ "create[installs a new jail inside ezjail\'s scope]" \ "cryptostart[start the encrypted jails]" \ "delete[removes a jail from ezjail\'s config]" \ "install[create the basejail from binary packages]" \ "list[list all jails]" \ "restart[restart a running jail]" \ "restore[create new ezjails from archived versions]" \ "start[start a jail]" \ "stop[stop a running jail]" \ "update[create or update the basejail from source]" fi }
compadd: pour construire les complétions au fur et à mesure
compaddest le builtin utilisé par_arguments,_valueset les autres fonctions pour ajouter les candidats à la complétion. Il y a certains cas où il est plus facile d'ajouter un à un les candidats. C'est le cas pour lister les jails : une première version utilisait quelque chose de la forme :_ezjail_running_jails () { _values : `_ezjail_list_jails running` } _ezjail_list_jails () { local jailcfgs="/usr/local/etc/ezjail" local state=$1 local j ( cd $jailcfgs && echo * ) | while read j; do case $state in running) [[ -f /var/run/jail_${j}.id ]] && echo $j ;; stopped) [[ -f /var/run/jail_${j}.id ]] || echo $j ;; *) echo $j ;; esac done }
Le problème est que lorsque la sortie de
_ezjail_list_jailsest vide,_valuesremonte un message d'erreur parce qu'on ne lui a donné aucun argument. Pour corriger cela, une première solution pourrait être de capturer la sortie de_ezjail_list_jailsdans une variable, tester si cette variable est vide ou non, et agir en conséquence. La deuxième solution, qui est celle que j'ai retenu, est de faire ajouter à_ezjail_list_jailsles complétions elles-mêmes. Il faut encore gérer à part le cas où il n'y a pas de candidats à la complétion, en revoyant 1 dans ce cas ; mais c'est plus facile à gérer. Au passage, la première version ne renvoyait pas 1 en l'absence de candidates… L'implémentation ressemble à ceci :_ezjail_running_jails () { _ezjail_list_jails running } _ezjail_list_jails () { local jailcfgs="/usr/local/etc/ezjail" local state=$1 local ret=1 local j for j in $jailcfgs/*(:t) ; do case $state in running) [[ -f /var/run/jail_${j}.id ]] && compadd $j && ret=0 ;; stopped) [[ -f /var/run/jail_${j}.id ]] || compadd $j && ret=0 ;; *) compadd $j && ret=0 ;; esac done return $ret }
compadd, en tant que brique de base, permet bien plus que de simplement ajouter un candidat. Encore une fois, allez voir la documentation pour tous les détails.
- Exemple typique
- Style
Le code de complétion est lancé à chaque fois que l'utilisateur tapotte sa touche
TABouC-d. Le code doit donc être raisonnablement rapide.Par ailleurs, le code de complétion s'exécute dans le shell courant de l'utilisateur. En particulier :
- le code n'a pas le droit de faire un
exit; - il ne peut pas afficher de chose sur
std{out,err}sans faire une horrible mixture entre le prompt, les propositions de complétion et ce qui est affiché ; - il faut penser à retourner 1 si on n'a pas de candidats à la complétion ;
- toutes les variables utilisées doivent être déclarées avec
local, pour éviter d'écraser ou de polluer les variables du shell courant de l'utilisateur ; - on écrit du code pour zsh, on a toute latitude pour écrire du code qui n'est pas POSIX.
Il y a également
completion-style-guide, qui est chez moi dans/usr/local/share/doc/zsh(copie en ligne), qui donne des conseils. J'ai découvert ce fichier un peu tard, et la complétion pour ezjail ne suit pas toujours à la lettre les conseils donnés.Bien sûr, lorsqu'on a quelque chose qui marche, on le propose au projet en question, ou alors directement sur la liste
zsh-workers@, pour en faire profiter les petits copains. - le code n'a pas le droit de faire un
À voir
A User's Guide to the Z-Shell, Peter Stephenson, Chapter 6: Completion, old and new. Il y a en particulier un tutorial bien fait.
The Z Shell Manual, 20. Completion System, et en particulier 20.6
Utility Functions. Vous en avez certainement une version accessible en
local avec info zsh (ou C-h i m zsh depuis emacs). Le manuel est
assez aride, je ne l'ai utilisé que comme référence.
zsh completion support for ezjail, de votre serviteur.
Déménagement
Écrit le lundi 2 mai 2011.
Déménagement…
23c23 < TIMEZONE="Europe/Paris" --- > TIMEZONE="Europe/Brussels"
emacs dans Tron
Écrit le vendredi 8 avril 2011.
L'info fait le tour des blogs sur emacs: emacs est utilisé dans Tron 2.0. Plus précisément, eshell est utilisé pour tuer la vidéo que Sam Flynn utilise pour se moquer du conseil d'administration. jtnimoy, derrière les effets spéciaux du film, donne tous les détails.
emacs était déjà visible dans The Social Network, où Big Brother
Zuckerberg dit qu'il est « temps de sortir emacs pour modifier un
script Perl ».
emacs est une star, vi ne peut vraiment pas en dire autant…
Archives. Il y a un flux Atom / RSS.
Footnotes:
Il serait certainement possible de laisser /usr hériter de
zroot/slashXX, et ainsi il n'y aurait qu'un seul point de montage à
déplacer.